Batch Loudness for Dolby Atmos Album Assembler
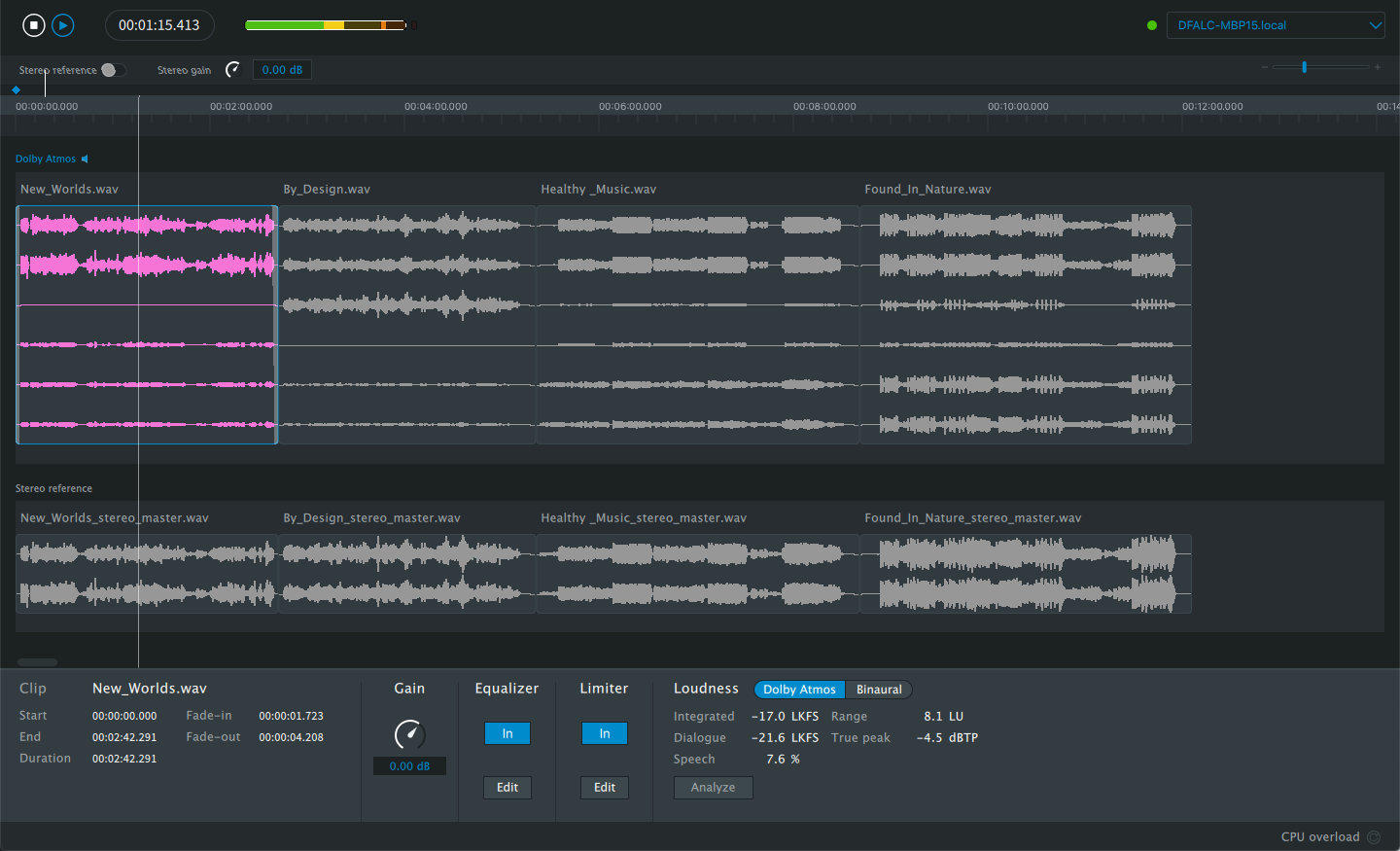
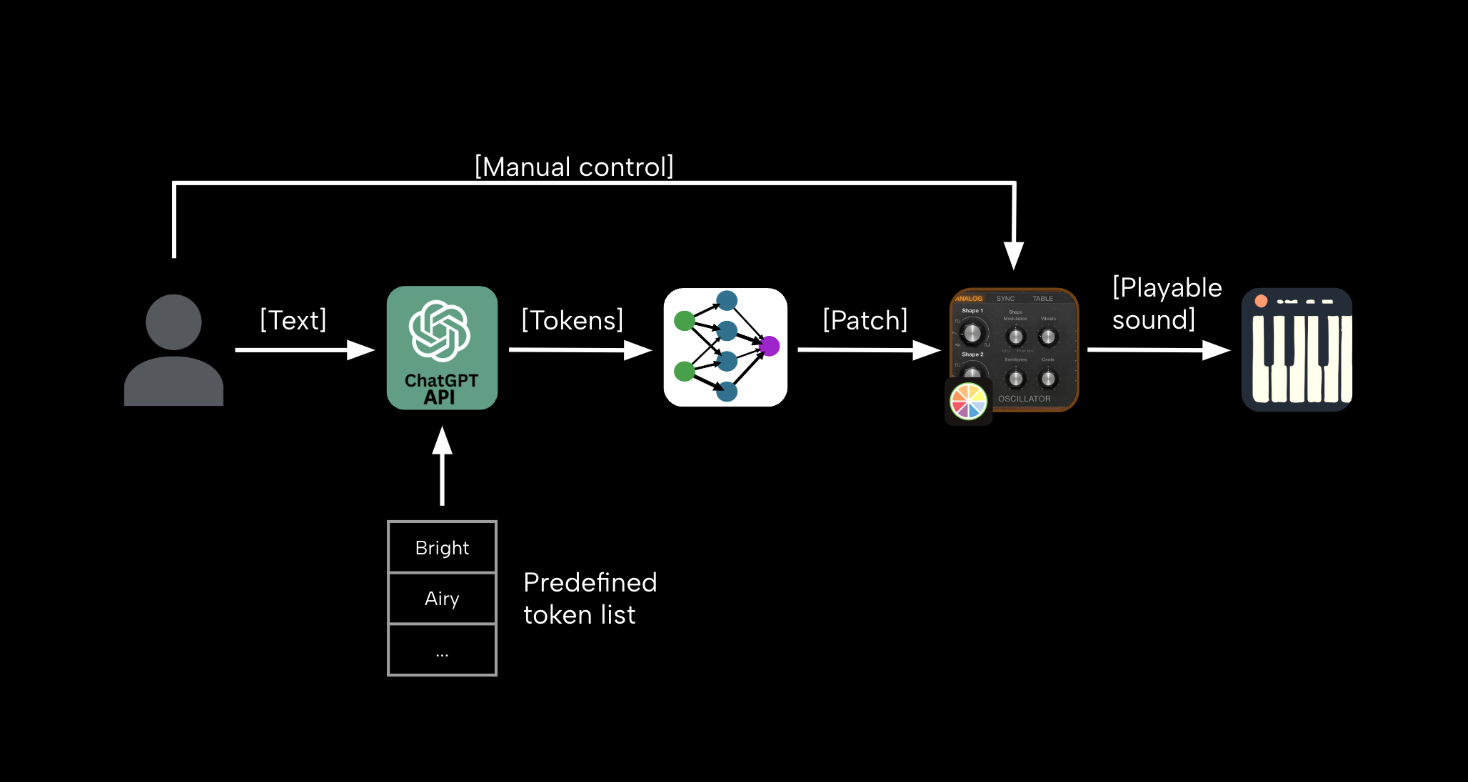
A script for the Soundflow platform which automates the process of loudness analysis in the Dolby Atmos Album Assembler. I wrote this function alongside Dolby Atmos mix engineer Luke Argilla to address a pain point in his workflow. The impetus for this project was that for projects with either a large number of tracks or particularly long tracks, the process of individually analyzing each track can be prohibitively time consuming. With this script, an Atmos mastering engineer can set up their DA3 session and walk away to do other work while every track in the session is analyzed. The code for this project is hosted on my Github. Feel free to use it, tweak it, and let me know if it's helped you at all!